Migrating from OpenAI to Muna.
Installing Muna
We provide SDKs for common development frameworks:Run your First Inference
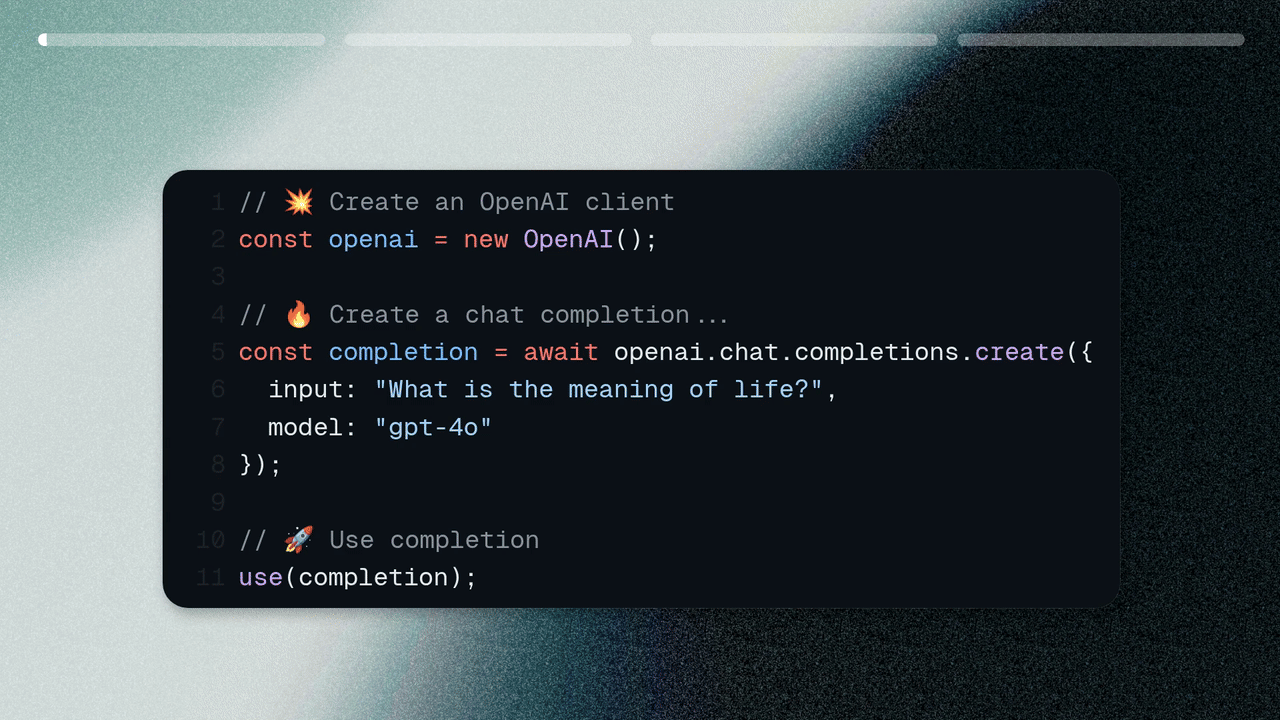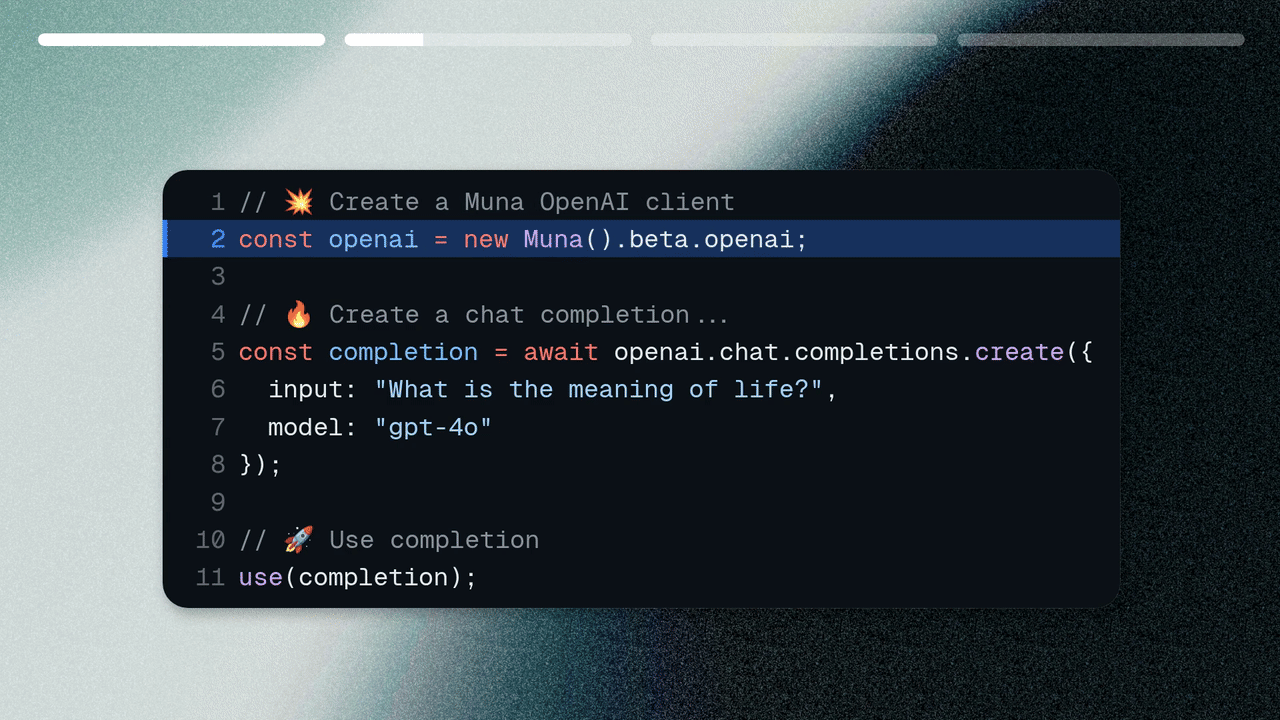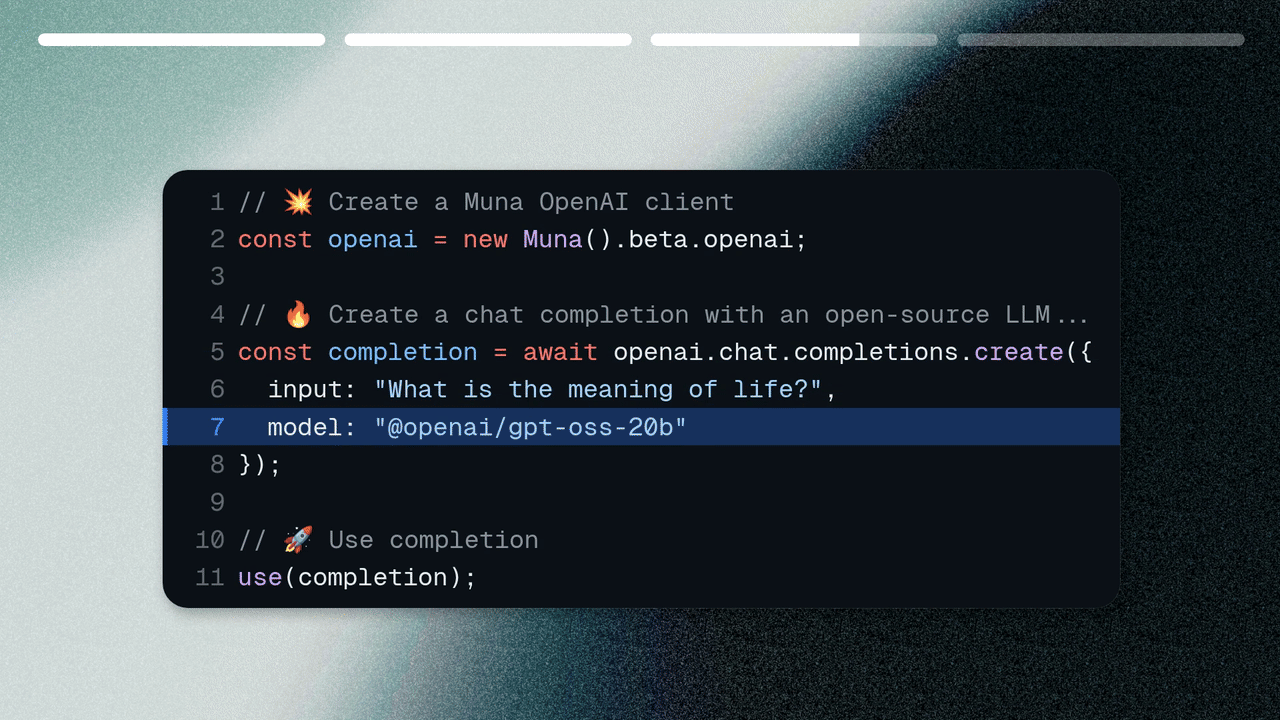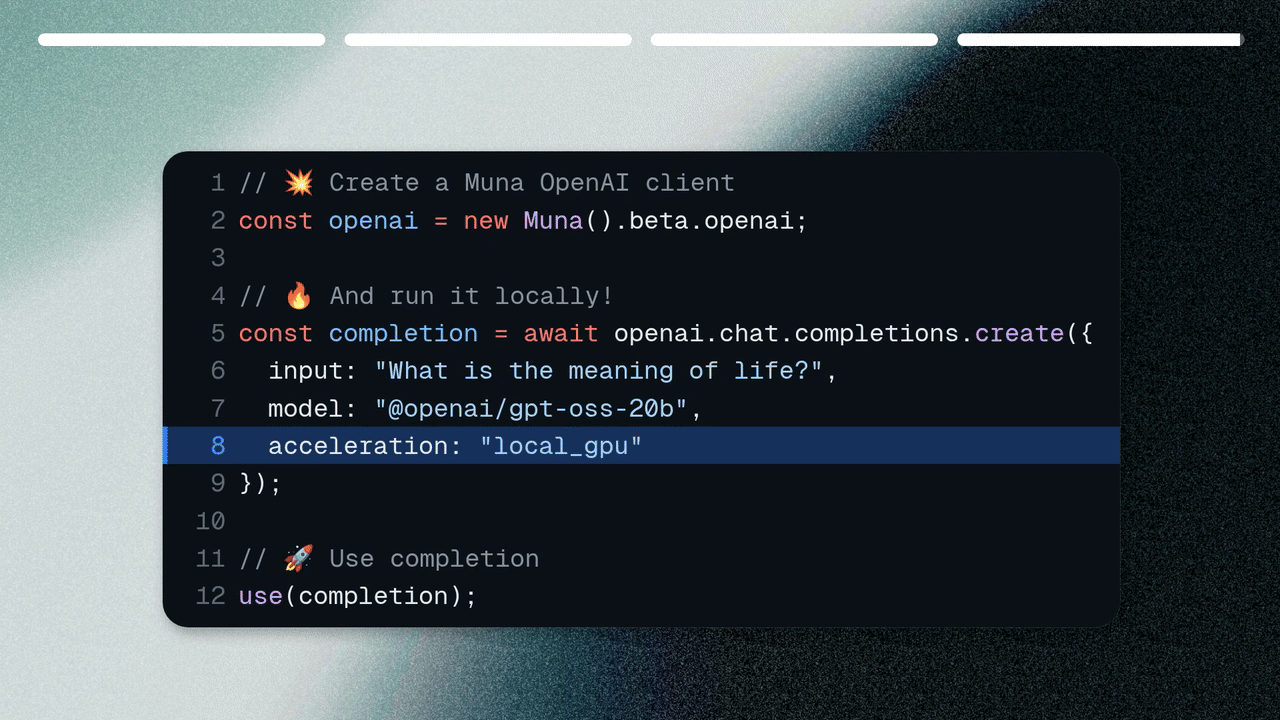
Generate an access key, then create a chat completion locally with@openai/gpt-oss-20b.
Run on a Datacenter GPU
Muna’s central feature is the ability to choose where inference runs, on each request. Let’s run the same model on a datacenter GPU:Next Steps
With Muna, you control which model to run, and where to run it, with zero infrastructure setup.Explore Models
Explore some popular models you can use immediately.
Join the Conversation
Come learn more and ask questions in our community Slack.