import { Muna } from "muna"// 💥 Create an OpenAI clientconst openai = new Muna({ accessKey: "..." }).beta.openai;// 🔥 Create a chat completionconst completion = await openai.chat.completions.create({ model: "@openai/gpt-oss-20b", messages: [{ role: "user", content: "What is the capital of France?" }]});// 🚀 Print the resultconsole.log(completion.choices[0]);
Our OpenAI-style client in muna.beta.openai that has the same interface
as the official OpenAI client. This allows you to migrate in two lines of code.
The first time you run the code above might take a few minutes, because we have to download the (rather large) model weights. Subsequent runs should take a few seconds.
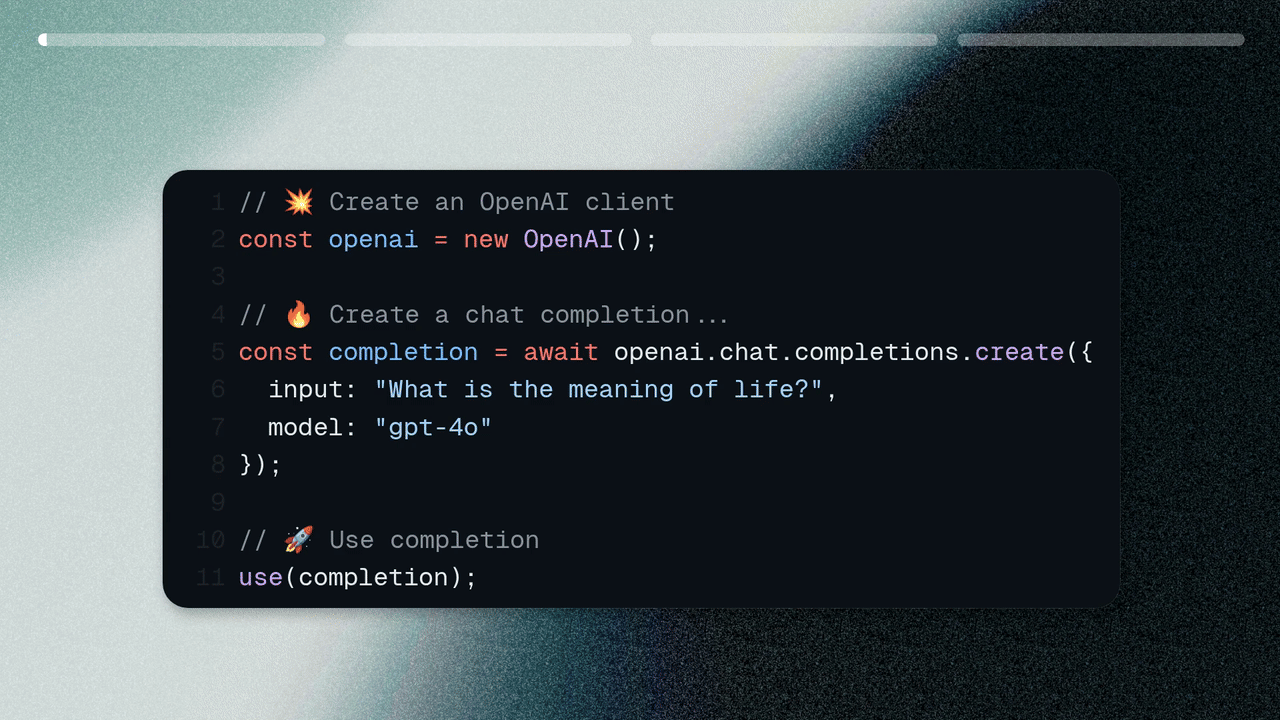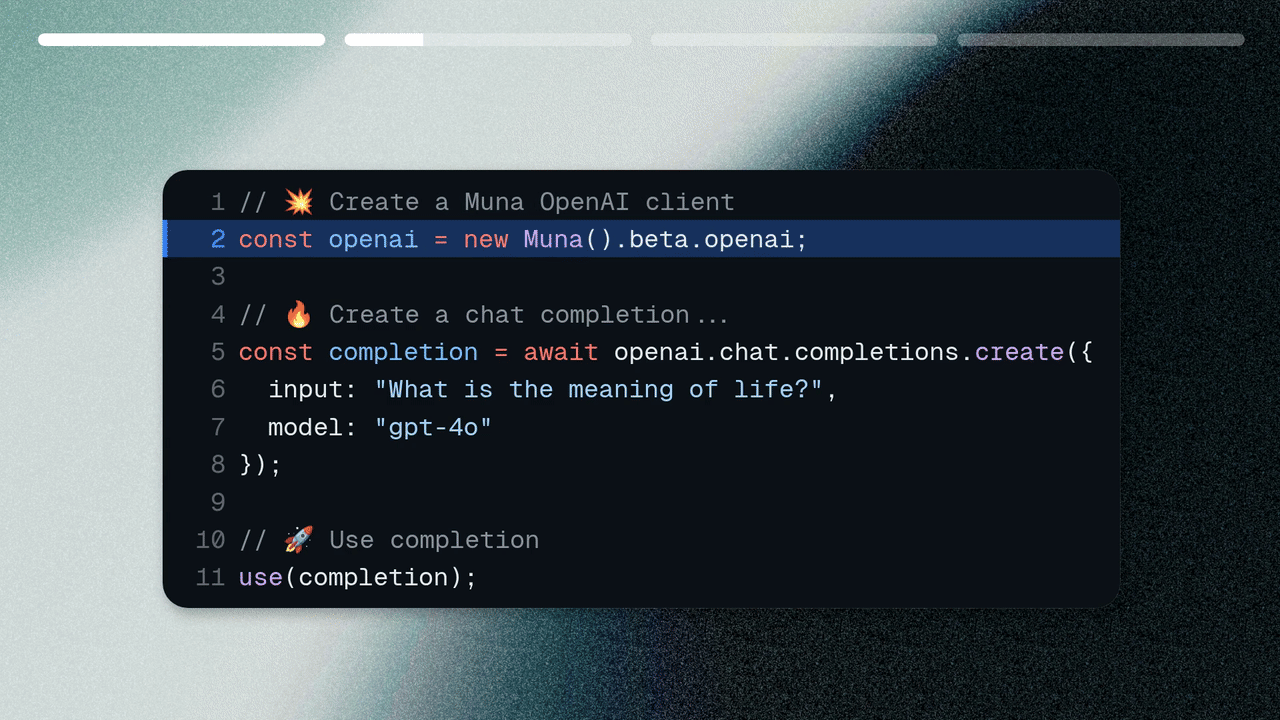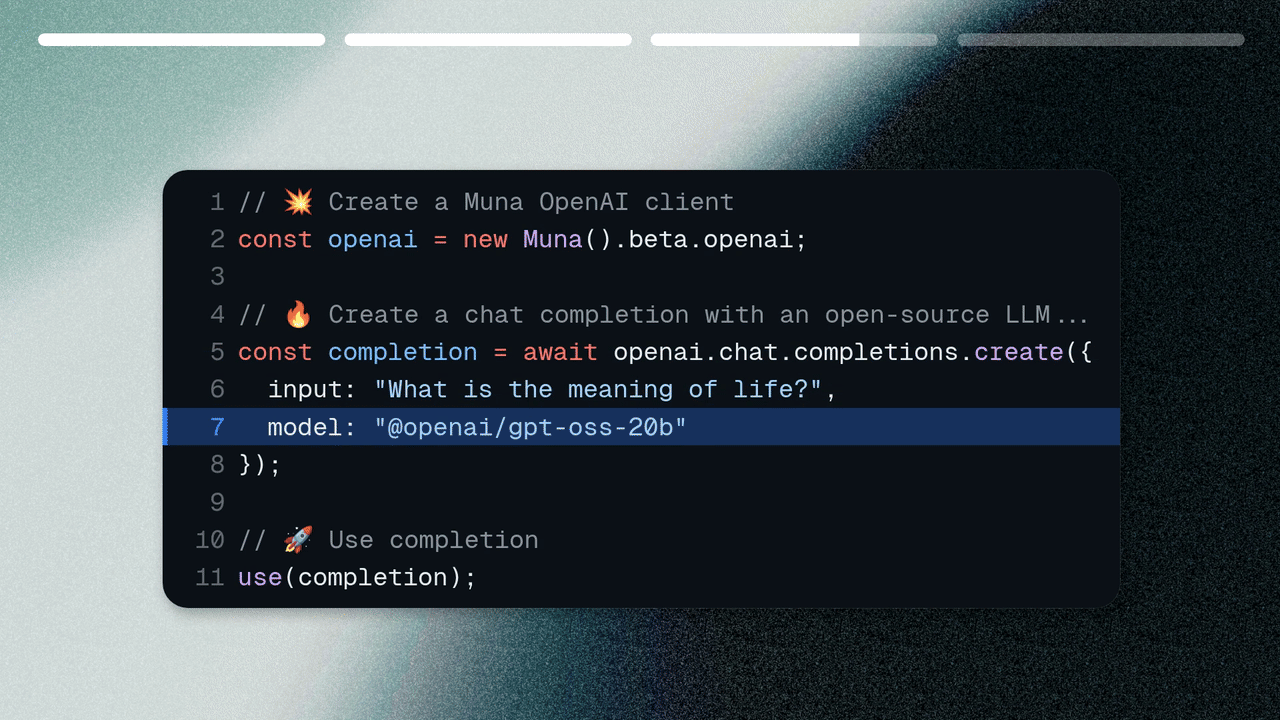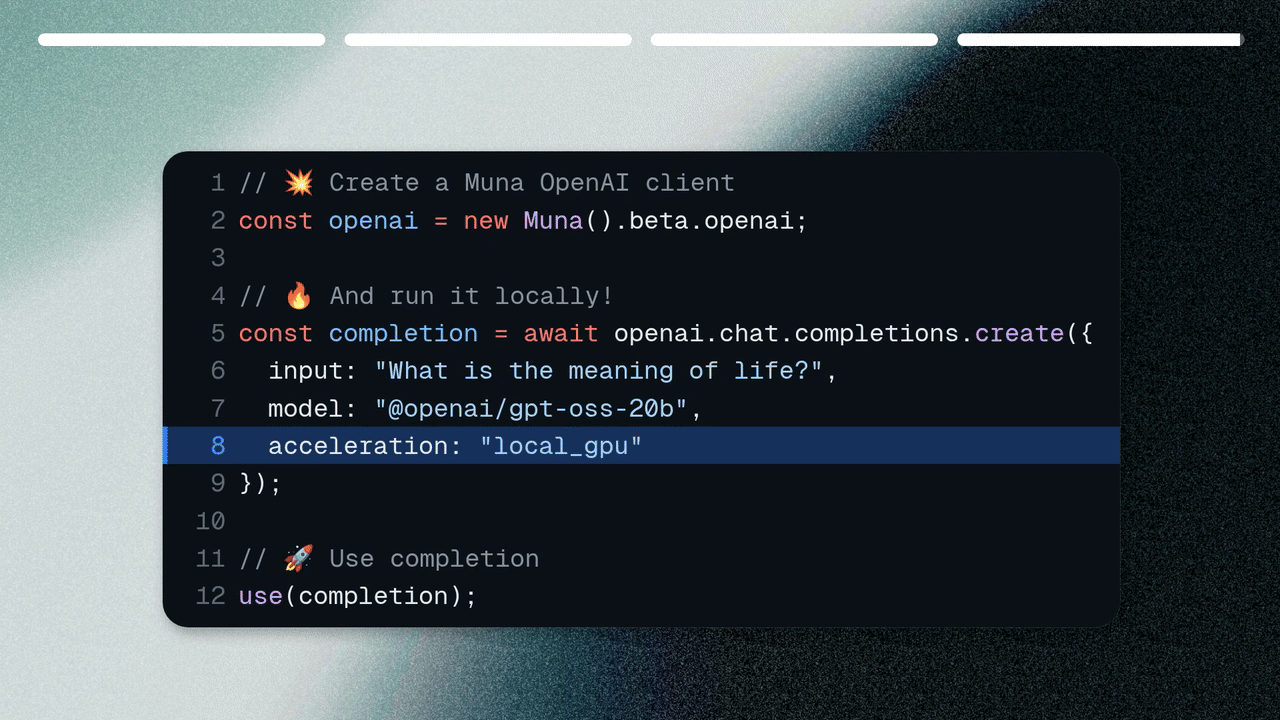
Muna’s central feature is the ability to choose where inference runs, on each request. Let’s run
the same model on a datacenter GPU:
// 🔥 Create a chat completion with a datacenter GPUconst completion = await openai.chat.completions.create({ model: "@openai/gpt-oss-20b", messages: [{ role: "user", content: "What is the capital of France?" }], acceleration: "remote_a100"});